
Data Accuracy: Why It Matters More Than Volume for Business Intelligence
Data accuracy is the degree to which data values correctly represent the real-world entities, events, or conditions they describe. An accurate customer record contains the customer's actual current name, address, phone number, and account status. An inaccurate record contains values that were wrong at entry, have decayed over time, or were corrupted during system transfers. Accuracy is one of nine data quality dimensions defined by the DAMA-DMBOK 2.0 framework, and it is the dimension that most directly determines whether business intelligence outputs reflect reality or fiction.
Sustaining accuracy at scale is the job of enterprise data cleaning workflows — governed, automated, and monitored over time rather than run as one-off projects.
According to Gartner, poor data quality costs organizations an average of $12.9 million per year. The McKinsey Global Institute found that poor-quality data can lead to a 20% decrease in productivity and a 30% increase in costs. These losses are disproportionately driven by accuracy failures: a complete, timely, and consistent record that contains the wrong values is worse than an obviously incomplete record, because inaccurate data gets used with confidence while incomplete data triggers investigation. This guide explains what data accuracy means in enterprise contexts, how to measure it, and how to build systems that maintain it. For broader data quality context, see our data cleansing guide.
Key Takeaways
- ✓Data accuracy measures whether values correctly represent real-world entities. It is the quality dimension with the highest impact on BI and AI reliability.
- ✓Accuracy is distinct from validity (format correctness) and completeness (field population). A record can be valid and complete but entirely inaccurate.
- ✓Accuracy degrades continuously: contact data decays at approximately 2% per month. Without monitoring, a clean database loses 22% accuracy within a year.
- ✓Measuring accuracy requires comparison against authoritative reference sources, not just internal consistency checks.
- ✓Inaccurate data in regulated industries (healthcare, finance) creates compliance risk under HIPAA, SOX, and GDPR Article 5(1)(d).
What Is Data Accuracy and How Does It Differ from Data Quality?
Data quality is the umbrella term covering all dimensions that determine whether data is fit for its intended use. The DAMA-DMBOK 2.0 framework defines nine dimensions: accuracy, validity, completeness, integrity, uniqueness, timeliness, consistency, currency, and reasonableness. Data accuracy is one specific dimension within that framework.
The distinction matters because data can score well on every other dimension and still be inaccurate. A customer record with a properly formatted email address (valid), a populated phone field (complete), the same values across all systems (consistent), and a recent update timestamp (timely) might still contain the wrong email address, wrong phone number, and wrong company name. Only comparison against the actual real-world entity reveals accuracy problems.
This is why accuracy is the hardest dimension to automate. Validity can be checked with format rules. Completeness can be measured with null counts. Consistency can be verified by comparing systems. Accuracy requires an external reference point: a verified address database, a confirmed customer interaction, or a third-party data source that reflects current reality.
Why Does Data Accuracy Matter More Than Data Volume?
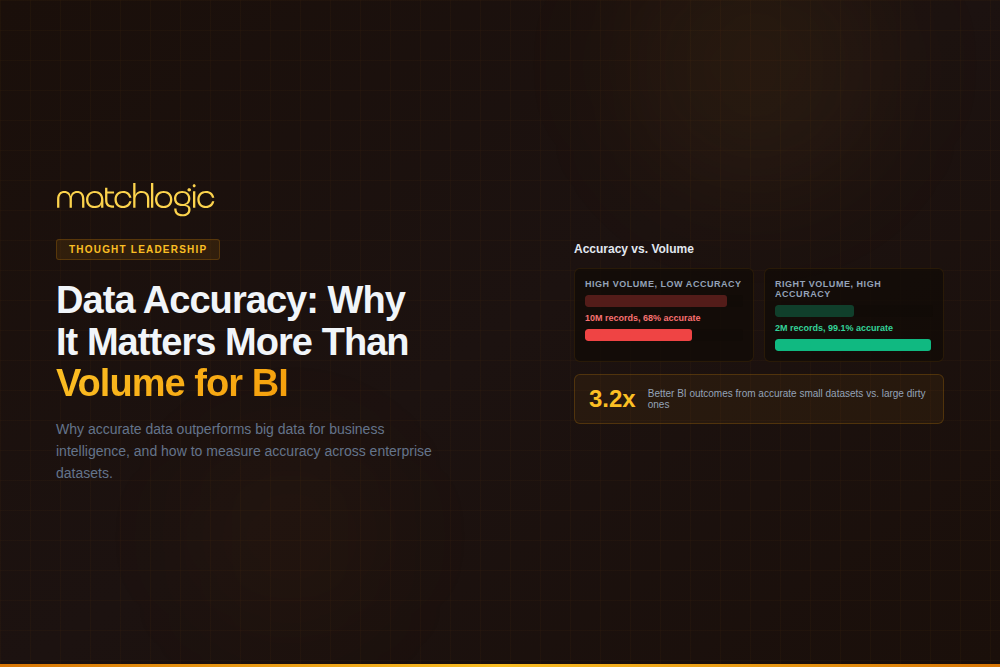
Enterprise organizations frequently prioritize collecting more data over verifying the accuracy of data they already have. This creates a compounding problem: larger datasets with embedded inaccuracies produce BI dashboards, AI models, and reports that look authoritative but reflect a distorted version of reality.
Consider a retailer with 5 million customer records used for marketing segmentation. If 15% of those records contain inaccurate demographic data (wrong age bracket, outdated address, incorrect purchase history attribution), every campaign targeting decision based on that segmentation is flawed. The retailer is not making decisions with 5 million data points; they are making decisions with 4.25 million accurate data points and 750,000 sources of error that silently skew every analysis.
For AI and machine learning applications, accuracy problems are even more damaging. Models trained on inaccurate data learn patterns that do not exist in the real world. A churn prediction model trained on customer records where 12% of the "last purchase date" values are incorrect will produce predictions that appear statistically valid but fail in production because the underlying patterns were artifacts of data errors, not actual customer behavior.
How Does Data Accuracy Compare to Other Quality Dimensions?
| Dimension | What It Measures | Example Pass | Example Fail (Despite Other Passes) |
|---|---|---|---|
| Accuracy | Values correctly represent real-world entities. | Customer name matches their legal name; address matches their current residence. | Record shows "123 Oak St" but customer actually lives at "456 Elm Ave." All other dimensions pass. |
| Validity | Values conform to expected formats and rules. | Email field contains "user@domain. com" (valid format). | Email passes format check but the address does not belong to this customer. |
| Completeness | All required fields contain values. | All 15 required fields are populated. | All fields populated, but 3 contain values from a different customer (data entry error). |
| Consistency | Same value appears the same way across systems. | Customer name is "John Smith" in CRM, billing, and ERP. | All systems agree the name is "John Smith" but the customer's actual name is "Jon Smith." |
| Timeliness | Data is current enough for its intended use. | Record updated within the last 30 days. | Record updated yesterday with the wrong address (timely but inaccurate). |
How Do You Measure Data Accuracy?
Accuracy measurement requires comparing data values against authoritative reference sources. There is no way to assess accuracy by examining data in isolation. Three measurement approaches apply to different enterprise scenarios.
1. Reference Data Comparison
Compare field values against verified external databases. Address accuracy can be measured by matching records against USPS CASS-certified address files. Company names can be validated against D&B or SEC EDGAR registrations. This approach works for structured fields with available reference sources and produces quantifiable accuracy percentages.
2. Statistical Sampling and Manual Verification
For fields without external reference sources (internal account notes, custom classification codes, relationship mappings), select a statistically representative sample and manually verify accuracy against source documents. A sample of 384 records from a 1-million-record dataset provides 95% confidence with a 5% margin of error, making manual verification practical even for large datasets.
3. Cross-System Reconciliation
When the same entity exists in multiple systems, compare values across systems and investigate discrepancies. If a customer's address differs between CRM and billing, at least one system is inaccurate. Cross-system reconciliation does not prove accuracy (both systems could be wrong), but it identifies records with a high probability of inaccuracy for targeted verification.
What Does Inaccurate Data Cost in Practice?
A 300-physician medical group operating across 12 clinics discovered during a HIPAA audit that 9.2% of patient records contained address inaccuracies: addresses that were valid (correctly formatted), complete (all fields populated), and consistent (matching across their EHR and billing systems), but wrong (patients had moved, and the records had not been updated).
These inaccurate addresses caused 14,000 misdirected patient communications per year, including appointment reminders, billing statements, and lab results. Three of those misdirected communications contained protected health information (PHI) sent to the wrong physical address, creating reportable HIPAA breaches. The estimated cost: $186,000 in breach notification and remediation expenses, plus $41,000 in returned mail and re-processing costs annually.
After implementing address verification against USPS reference data and scheduled re-validation every 90 days using MatchLogic's automated profiling and standardization pipeline, the medical group reduced address inaccuracy from 9.2% to 1.4% within 6 months and eliminated PHI misdirection incidents entirely.
Visual Reference
Frequently Asked Questions
What is data accuracy?
Data accuracy is the degree to which data values correctly represent the real-world entities, events, or conditions they describe. It is one of nine data quality dimensions in the DAMA-DMBOK 2.0 framework. Unlike validity (format correctness) or completeness (field population), accuracy can only be verified by comparing data against authoritative external reference sources or direct verification with the real-world entity.
What is the difference between data accuracy and data quality?
Data quality is the umbrella concept encompassing all dimensions that determine fitness for use: accuracy, validity, completeness, consistency, timeliness, integrity, uniqueness, currency, and reasonableness. Data accuracy is one specific dimension within that framework. A record can have high quality on most dimensions (valid, complete, consistent, timely) while still being inaccurate if its values do not match reality.
How do you improve data accuracy?
Three approaches work in combination: validation against external reference data (USPS addresses, D&B company records), automated profiling to detect statistical anomalies that indicate accuracy problems, and scheduled re-verification cycles to catch accuracy decay from contact changes and data aging. Platforms like MatchLogic integrate all three into a single pipeline. For financial services accuracy requirements, see our guide on data accuracy in financial services.
Why is data accuracy important for AI and machine learning?
AI models learn patterns from training data. If 12% of training records contain inaccurate values, the model learns patterns that do not exist in the real world. These "phantom patterns" produce predictions that appear statistically valid during testing but fail in production. According to McKinsey, poor-quality data is among the primary reasons generative AI adoption at scale has faced challenges.





.svg)