
Data Cleaning for Enterprise: Building Repeatable Data Quality Workflows
Enterprise data cleaning is the practice of building repeatable, automated workflows that detect and correct data errors across an organization's systems on an ongoing basis. It is the operational half of a data cleansing program: the program sets the standards, assigns stewardship, and defines the quality dimensions, and cleaning is what enforces those standards on every record that arrives.
The distinction matters because most organizations still run cleaning as a project. They clear a backlog, declare victory, and watch quality regress within about 90 days. The State of Enterprise Data Quality 2024 report from Anomalo found that 95% of enterprise data leaders had a data quality issue with direct business impact, and 100% reported quality issues in their warehouses and lakes.
Those numbers persist because the sources of bad data keep operating after the cleanup ends. New records arrive with the same inconsistencies, existing records decay, and no one owns the rules that would have caught either.
Why Does One-Time Data Cleaning Fail at Enterprise Scale?
One-time cleaning fails because the sources of dirty data keep operating after the project ends. A major initiative (a CRM migration, an audit, an analytics launch) triggers a cleaning sprint. The team spends months scrubbing records, standardizing formats, and removing duplicates, the data looks good, and within about 90 days quality regresses to pre-cleanup levels.
The regression is predictable. New records enter with the same inconsistencies, and existing records decay as contacts change roles, companies merge, and addresses change. A database that is clean today loses accuracy over the year without ongoing maintenance.
The fix is architectural, not procedural. Enterprise cleaning runs as a continuous function embedded in pipelines: automated rules fire at ingestion, scheduled batch processes catch drift, and monitoring surfaces degradation before it reaches reports or models.
What Data Quality Dimensions Should Enterprise Cleaning Address?
The DAMA-DMBOK framework from DAMA International provides a vendor-neutral vocabulary of data quality dimensions that lets teams measure and communicate quality consistently across systems. Most enterprise programs begin with the four dimensions that carry the highest operational impact: accuracy, completeness, consistency, and timeliness.
The remaining dimensions (validity, integrity, uniqueness, currency, and reasonableness) become relevant as the program matures. Validity and integrity checks usually arrive in the first expansion cycle, followed by uniqueness once the organization builds matching and deduplication capability.
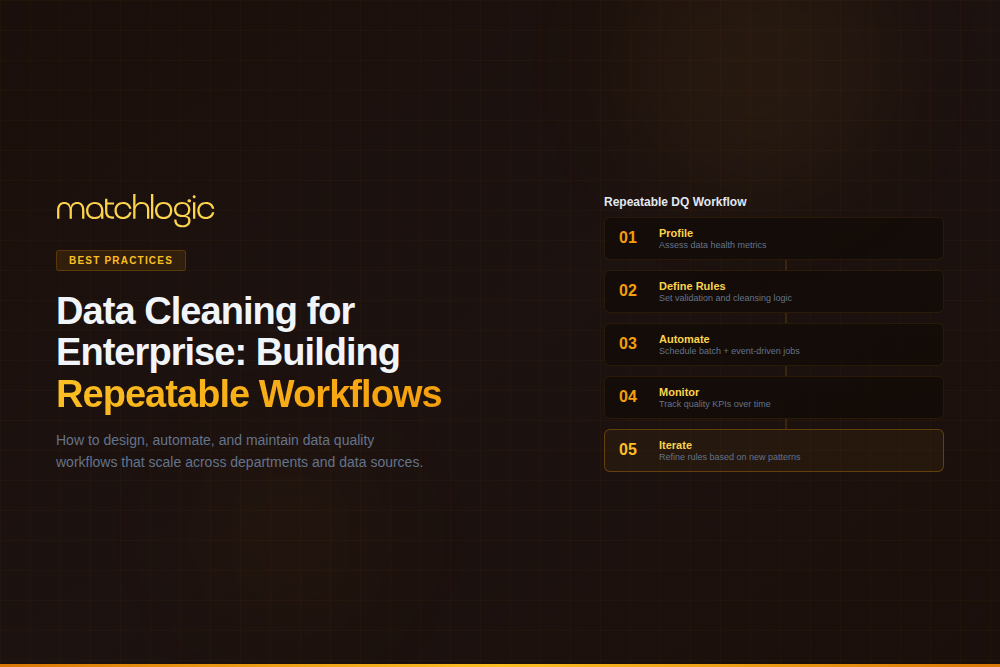
What Does a Repeatable Enterprise Data Cleaning Workflow Look Like?
A repeatable workflow converts ad hoc cleaning into a governed, measurable operation through six phases: scope, profile, define rules, execute, embed, and monitor. Each phase has a defined input, output, responsible role, and tooling requirement.
Phase 1: Scope and Prioritize
Not all data warrants the same cleaning effort. Map datasets to business criticality and regulatory exposure. Customer master data feeding clinical systems demands higher standards than a newsletter list. Output: a ranked dataset list with a quality tier (Tier 1 regulatory or mission-critical, Tier 2 operational, Tier 3 informational).
Phase 2: Profile and Baseline
Run automated profiling across every Tier 1 and Tier 2 dataset to establish a quantified quality baseline. Profiling reports completeness, format distribution, uniqueness, and outliers per field, and this baseline becomes the reference for all later improvement. Our data profiling tools guide covers the methodology. Output: a profiling report ranking issues by record volume affected.
Phase 3: Define Rules and Thresholds
Translate profiling findings into testable rules. Each rule specifies the condition it detects, the transformation it applies, and the dimension it addresses. A rule that standardizes Calif to CA is safe to automate; a rule that changes a legal name needs human approval. Output: a versioned rule library with severity and automation classifications.
Phase 4: Execute and Validate
Apply rules to prioritized datasets in a staging environment before production. Validate against the baseline: did completeness rise from 72% to 95%? Flag any rule that produced unexpected changes. Output: cleaned datasets with before/after scores, a change log, and a manual-review list.
Phase 5: Embed in Pipelines
Move validated rules from batch execution into real-time pipelines so they fire at ingestion and keep dirty records out of production. API integration with ETL/ELT tools, CRMs, ERPs, and warehouses routes every new record through the same quality gates that cleaned the backlog. Output: rules deployed as pipeline stages with event-triggered and scheduled modes.
Phase 6: Monitor and Improve
Deploy dashboards that track each dimension over time and set alert thresholds (for example, completeness below 90% or duplicate rate above 5% notifies the assigned steward). Review rule performance quarterly, retire rules that fire on under 0.1% of records, and convert new error patterns into new rules. Output: quality dashboards, automated alerts, and a quarterly review cadence.
Who Owns Enterprise Data Cleaning?
Enterprise cleaning programs fail most often when ownership is ambiguous. A large share of data governance initiatives stall for exactly this reason: no one is accountable for the rules, so exceptions accumulate and the program drifts back to its ad hoc state. The RACI model below maps cleaning responsibilities to the roles that typically exist in enterprise data teams.
The data steward role is the operational backbone of this model. Data stewards own the cleaning rules for their domain (customer data, vendor data, product data), review records flagged for manual intervention, and report quality metrics to the CDO. Without designated stewardship, rules drift, exceptions accumulate, and the cleaning program degrades into the same ad hoc state it was designed to replace.
How Does Enterprise Data Cleaning Work in Practice?
A mid-market insurance company with 1,200 employees ran three core systems: a Salesforce CRM with 2.8 million policyholder records, a Guidewire claims system with 4.1 million claims records, and a legacy underwriting system with 1.6 million policy records. Before a continuous cleaning program, the data team spent about 35% of its time on reactive fixes triggered by failed downstream reports.
Profiling all three systems found that 41% of policyholder records had inconsistent name formats across systems, 28% of claims records referenced policy numbers absent from the underwriting system (orphaned references), and 19% of address records held format variations that blocked automated correspondence.
After a six-phase workflow with 47 automated rules and 3 assigned stewards, the company cut reactive fix time from 35% to 8% of the team's capacity within 6 months. The rules caught roughly 12,400 errors per week at ingestion, preventing them from reaching claims processing and regulatory reporting. Measured outcomes: about $340,000 in annual rework savings, about $180,000 in avoided penalties from more accurate commissioner filings, and a 14% improvement in claims cycle time.
What Should Enterprise Teams Look for in Data Cleaning Tools?
Enterprise cleaning tools must support the full six-phase workflow, not just the execution phase. Tools that clean records without profiling, versioning, monitoring, and pipeline integration force teams to build the rest themselves, and that infrastructure rarely survives organizational change.
The critical differentiator is whether the tool treats cleaning as an isolated function or as part of an integrated pipeline. MatchLogic combines profiling, standardization, and cleaning in MatchCore and resolves records across systems (the uniqueness dimension) through MatchSense, so every rule, transformation, and quality score lives in one auditable system. For regulated industries this satisfies the lineage requirements of SOX Section 404, HIPAA, and the GDPR accuracy principle, which requires personal data to be accurate and kept up to date.
Deployment model is the other non-negotiable criterion. Organizations processing PHI, financial PII, or government records under sovereignty rules need on-premise or private-cloud deployment where all processing stays inside the controlled environment. The uniqueness dimension in particular depends on deduplication capability that runs on the same governed data.
Frequently Asked Questions
What is enterprise data cleaning?
Enterprise data cleaning is the practice of building repeatable, governed workflows that detect and correct data errors across systems continuously. Unlike one-time cleanup, it embeds quality rules into pipelines, assigns ownership through stewardship roles, and measures outcomes against defined quality dimensions from the DAMA-DMBOK framework.
How often should enterprise data be cleaned?
Continuously, not periodically. The most effective programs apply rules at ingestion in real time and run supplemental batch processes daily or weekly. Records decay as people change roles and companies merge, so quarterly or annual cleaning projects cannot keep pace with the rate at which new errors enter.
What is the DAMA-DMBOK framework for data quality?
The DAMA-DMBOK is a vendor-neutral body of knowledge published by DAMA International that defines data quality dimensions and stewardship practices. It provides standardized vocabulary and measurement approaches and is widely used as the basis for quality metrics, steward role definitions, and the CDMP certification.
How do you measure the ROI of enterprise data cleaning?
Track three categories: direct cost savings (reduced rework hours, eliminated duplicate mailing costs), risk avoidance (penalties and audit failures prevented), and operational efficiency (faster cycle times, less error investigation). The insurance program in this article reached about $520,000 in annualized savings against roughly $150,000 to implement.
Should enterprise data cleaning happen on-premise or in the cloud?
It depends on your regulatory environment and data classification. Organizations processing PHI under HIPAA, financial data under SOX and GLBA, or government records under FedRAMP cannot send production data to third-party cloud endpoints, so on-premise deployment is a compliance requirement. Others can evaluate cloud options against their governance policies.
What is the difference between data cleaning and data governance?
Data cleaning is an operational activity that fixes specific errors in specific records. Data governance is the organizational framework of policies, roles, and standards that defines how data is managed. Cleaning is one activity within a governance program; governance provides the authority and measurement that make cleaning sustainable.





.svg)