
Entity Matching Software: How Algorithms Identify the Same Real-World Object
Entity matching software uses algorithms to compare records from one or more databases and determine whether they refer to the same real-world entity: a person, organization, product, or location. Matching is the core comparison step within the broader entity resolution process, which also includes data preparation, blocking, clustering, and golden-record creation.
The accuracy of the matching stage sets the quality of everything downstream: if the algorithms cannot tell that “Robert J. Smith at 123 Main St.” and “Bob Smith at 123 Main Street, Apt. 2” are the same person, the resulting profiles, compliance reports, and analytics rest on fragmented data. This guide explains how the algorithms work, which fit which data types, and how to evaluate matching capability, the layer that feeds the wider entity resolution workflow.
How Is Entity Matching Different from Entity Resolution?
Entity matching is one stage in a multi-step pipeline, and entity resolution is the full process. Matching takes two records and produces a similarity score or a match decision, answering a narrow question: how likely is it that Record A and Record B describe the same entity? It does not group records into clusters, resolve conflicting values, or create golden records.
Entity resolution wraps matching in a larger process: ingestion, standardization, blocking, the matching stage, classification against thresholds, transitive clustering, survivorship, and golden-record persistence. When vendors say “entity matching software,” they usually mean the algorithms embedded within their entity resolution software platform, not a standalone tool. Clustering those matched pairs into resolved entities is the job of cross-source entity resolution data linkage.
What Algorithms Does Entity Matching Software Use?
Entity matching algorithms fall into five categories, and production-grade software combines algorithms from multiple categories in a layered pipeline, because no single algorithm handles every data type well. The same data matching techniques appear in any data quality workflow, framed there around cleansing rather than identity resolution.
String Similarity Algorithms
String similarity measures character-level distance. Levenshtein counts the minimum single-character edits to transform one string into another, so “Smith” and “Smyth” differ by 1. Jaro-Winkler is tuned for short strings and rewards a shared prefix, reflecting that first-character errors are rarer, while Damerau-Levenshtein also counts transpositions as a single edit.
These methods work well for typos, minor spelling variation, and abbreviation differences. They struggle with semantic equivalence (“Robert” vs. “Bob”), reordered tokens (“Smith, John” vs. “John Smith”), and strings of very different lengths.
Phonetic Algorithms
Phonetic algorithms encode strings by how they sound. Soundex, developed in the early 1900s for the US Census, encodes names into a letter-plus-three-digits code, so “Smith” and “Smythe” both become S530. Metaphone and Double Metaphone handle broader phonetic rules and produce multiple encodings for ambiguous names, and NYSIIS is tuned for names common in New York.
Phonetic methods are most useful for person-name matching where spelling varies but pronunciation is consistent. They produce false positives for names that sound alike but differ, and they do not apply to addresses, dates, or numeric identifiers.
Token-Based Algorithms
Token-based algorithms split strings into words and compare the sets. Jaccard similarity divides the intersection by the union of two token sets, while TF-IDF cosine similarity weights each token by how informative it is, so a common city name contributes less than a rare suite number.
These methods excel at address and company-name matching, where word order varies and tokens such as “Inc.” or “LLC” are noise. They handle long strings better than character-level methods because they are order-independent and can be weighted by token significance.
Probabilistic Matching
Probabilistic matching, grounded in the Fellegi-Sunter model (1969), weights each field comparison by its discriminating power, so agreement on a rare last name carries more weight than agreement on a common first name. The model sums per-field log-likelihood ratios into a composite score and can be estimated without labeled data using Expectation-Maximization, which matters for teams that cannot hand-label thousands of pairs.
AI-Based Matching
AI-based matching trains a classifier on labeled record pairs. Supervised methods such as gradient boosting and neural networks learn complex, non-linear patterns that rule-based and probabilistic methods miss, and active learning cuts the labeling burden by selecting the most informative pairs for review.
The trade-off is explainability. A classifier that returns a 0.87 probability without revealing which features drove it creates compliance challenges in regulated industries, so AI matching in those settings must expose feature importance. This is exactly the gap MatchSense closes, with pre-trained, deterministic, explainable AI entity resolution that returns a readable reason for every decision.
The table summarizes which algorithm fits which field type, with strengths, weaknesses, and cost.
How Do Entity Matching Algorithms Combine in a Production Pipeline?
Enterprise software does not run a single algorithm against all fields; it runs different algorithms on different fields and combines the results.
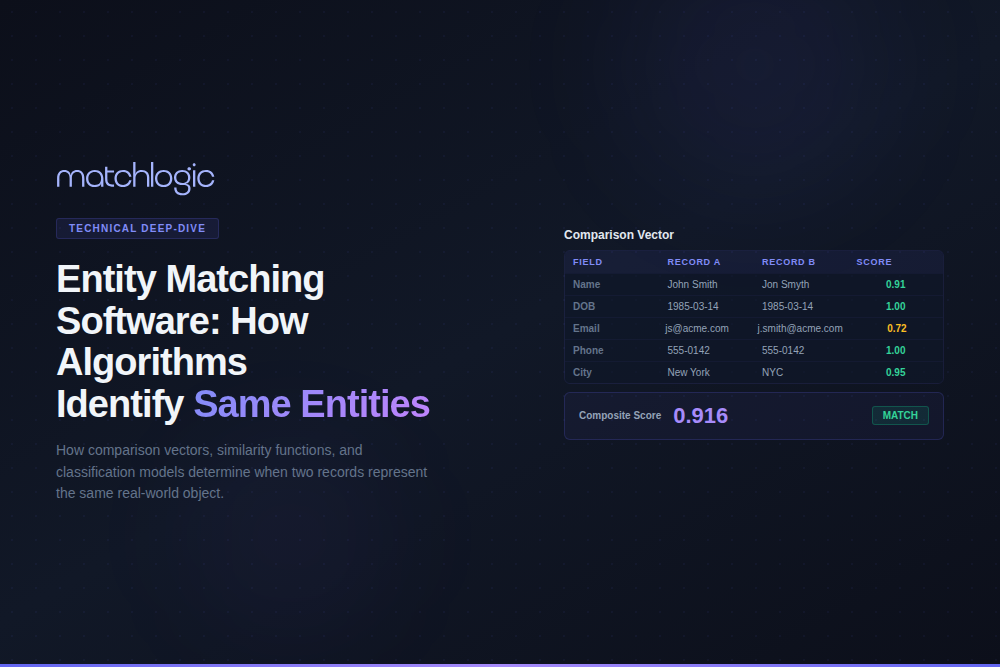
Layer 1 is field-specific comparison: Jaro-Winkler on first name (0.92), Jaro-Winkler and Double Metaphone on last name, TF-IDF cosine on the full address (0.85), exact match on date of birth, and a missing phone value in one record.
Layer 2 is composite scoring: the Fellegi-Sunter model assigns weights from each field's m-probability and u-probability, so a rare last name with a 0.88 score outweighs a common first name with a 0.92 score, and a missing field gets a neutral weight. Layer 3 is classification: the composite score is compared against an upper and a lower threshold, routing pairs to auto-match, auto-reject, or manual review, with the thresholds set by the business based on its tolerance for false positives versus false negatives.
How Should You Balance Precision and Recall in Entity Matching?
The precision and recall trade-off is the single most important configuration decision. Precision is the share of predicted matches that are correct, recall is the share of true matches the system finds, and increasing one typically lowers the other.
This is a business decision, not a technical one. In CRM deduplication, false positives merge two different customers and corrupt billing and reporting, so high precision is critical. In fraud detection, false negatives let a bad actor's records stay unlinked, so high recall is critical even at the cost of more borderline cases in review.
Software should let engineers set the trade-off per entity type and per job. Customer deduplication might require 98 percent precision with 90 percent recall, while sanctions screening might require 99.5 percent recall even if precision drops to 85 percent. MatchCore's configurable thresholds and field-level weights tune these trade-offs per matching job, with every per-field score visible.
What Does Algorithm Selection Look Like for a Real Data Challenge?
Consider a national retail chain with 8.5 million customer records across e-commerce, in-store POS, and a loyalty database, needing a unified customer view for personalization. The three systems store names differently: full legal names online, cashier-entered names in POS, and card-printed names in loyalty.
The team configures the pipeline by field. Names use Jaro-Winkler (threshold 0.82) plus Double Metaphone as a phonetic check, catching “Michael” versus “Micheal” and “Katherine” versus “Catherine.” Addresses use TF-IDF cosine (threshold 0.78), email uses exact match after lowercasing, and phone uses exact match after normalizing to 10 digits.
The composite layer uses Fellegi-Sunter weights calibrated against 800 labeled pairs reviewed by data stewards. The upper threshold captures 72 percent of true matches at 99.1 percent precision, the review zone captures another 18 percent, and the rest are classified as distinct. The complete pipeline reaches an F1 of 0.94, against 0.71 when the team previously matched on name plus email alone.
What Should You Look For in Entity Matching Software?
When evaluating matching capability within an entity resolution platform, focus on five factors.
- Algorithm breadth: Does it support string similarity, phonetic, token-based, probabilistic, and AI methods? Platforms limited to one or two types underperform on data they were not designed for.
- Field-level configurability: Can you assign different algorithms and thresholds to different fields? Names, addresses, dates, and identifiers each need different treatment.
- Transparency: Can you see which algorithm fired on which field, what score it produced, and how the composite formed? This is not optional in regulated industries, and MatchCore provides field-level match explanations for every decision.
- Threshold configurability: Can you set different precision and recall trade-offs per entity type and per job, and adjust them without re-running the entire process?
- Performance at scale: How does matching speed change from 1 million to 100 million records? The answer depends on blocking strategy, parallelization, and distributed-compute support.
Choosing Entity Matching Software for Your Data
Matching accuracy sets the ceiling for every downstream profile, report, and analysis, so evaluate algorithm breadth, field-level configurability, transparency, and scale before committing. For regulated enterprises, MatchCore delivers the string-similarity, phonetic, token-based, and probabilistic engine with transparent per-field scoring, and MatchSense adds explainable AI matching on the same on-premise footprint, so accuracy never comes at the cost of an audit trail.
Frequently Asked Questions
What is entity matching software?
Entity matching software uses algorithms to compare records and decide whether they refer to the same real-world entity. It is the comparison stage within entity resolution, applying string similarity, phonetic, token-based, probabilistic, and AI methods to calculate match scores, which are then classified against configurable thresholds into match, non-match, or possible-match decisions.
What is the difference between entity matching and fuzzy matching?
Fuzzy matching refers to the specific algorithms (Jaro-Winkler, Levenshtein, Soundex) that compare strings for approximate similarity. Entity matching is the broader process of applying fuzzy matching alongside probabilistic scoring, AI classification, and token-based comparison across multiple fields to produce a composite decision. Fuzzy matching is one tool within the entity matching toolkit.
Which algorithm is best for matching person names?
Jaro-Winkler is the most widely used for short person names because it is prefix-weighted and handles transposition errors well. For multilingual or phonetically variable names, combine it with Double Metaphone to catch both spelling and phonetic similarity. No single algorithm handles every variation, so effective name matching uses a combination.
How do I set the right match threshold?
Thresholds are a business decision driven by the cost of errors. If false positives are more costly than false negatives, set a higher threshold for higher precision. If missing a true match is more costly, as in fraud detection or compliance screening, lower the threshold for higher recall and route more borderline cases to manual review.
Can entity matching software handle multilingual data?
Some platforms can, many cannot. Multilingual matching requires Unicode support, language-specific phonetic algorithms, transliteration for non-Latin scripts, and awareness of name-ordering conventions. Verify multilingual capability with your actual data rather than marketing claims.
How does entity matching relate to data quality?
Matching accuracy depends directly on data quality, since unstandardized fields reduce recall. Profiling and standardization before matching meaningfully improve match accuracy, as documented in the standard reference text on the subject. Platforms that integrate profiling, cleansing, and matching in one pipeline remove the handoff that often introduces errors.





.svg)