
What Is Data Deduplication Software?
Data deduplication software is an enterprise data quality platform that detects, flags, and resolves duplicate records within and across databases, CRMs, data warehouses, and other structured data systems. It combines deterministic rules, fuzzy matching algorithms, phonetic encoding, and probabilistic scoring to identify records that represent the same real-world entity, whether a person, organization, location, or product, even when those records contain misspellings, abbreviations, formatting inconsistencies, or missing fields.
That core function separates it from the basic “find exact duplicates” features built into tools like Excel, Salesforce, or HubSpot. Native CRM deduplication relies on identical field values such as the same email or phone number, while enterprise software catches the other 30 to 40 percent of duplicates, the ones where “Robert J. Smith at 123 Main St.” and “Bob Smith, 123 Main Street, Apt. 2B” are the same person. Most teams overestimate the quality of what they are deduplicating. Research published in Harvard Business Review found that only 3 percent of company data met basic quality standards.
For enterprises building customer 360 views, running AI and machine learning models, or preparing for system migrations, deduplication is not an optional cleanup task. It is infrastructure, because every model, report, and migrated record inherits the quality of the data underneath it.
Why Do Native CRM and Database Tools Fall Short?
Salesforce includes a duplicate management feature that checks for exact matches on email, name, and phone at the point of record creation, and HubSpot offers a similar tool that flags contacts with identical email addresses. These features catch the obvious duplicates, perhaps 60 to 70 percent of the total, and miss everything else.
The gap is structural. Native tools compare single fields using exact-match or basic similarity, while enterprise deduplication software compares multiple fields at once, weights each field by reliability (email is more reliable than name, ZIP code more reliable than city), and produces a composite match score. A record pair that scores 45 percent on name similarity alone might score 92 percent once address, phone, and account number are factored in.
Native tools also lack survivorship logic. When Salesforce merges two contacts, it applies a simple “most recently modified wins” rule, whereas enterprise scenarios demand field-level control: keep the email from one system, the phone from another, and the address from whichever source was updated most recently. Without that granularity, every automated merge risks overwriting good data with bad.
How Does Enterprise Data Deduplication Software Work?
Enterprise deduplication follows a structured pipeline, where each stage builds on the output of the previous one and skipping any step degrades the accuracy of everything downstream.
Stage 1: Connect and Ingest
The platform connects to every data source in scope: CRMs, ERPs, data warehouses, flat files, APIs, and cloud applications. A mid-size financial services firm might connect Salesforce for customer records, SAP for billing, a legacy system for policy data, and three acquired-company databases, after which the platform normalizes those schemas into a unified record format for comparison.
Stage 2: Profile and Assess
Before any matching begins, the software profiles the ingested data to reveal field completeness, format consistency, value distributions, and a preliminary estimate of duplicate density. This prevents wasted effort: if a large share of address fields are blank, address-based blocking will miss those records, and the matching strategy must account for the gap.
Stage 3: Standardize and Cleanse
The platform normalizes values so matching algorithms compare equivalent representations, turning “Corp.” into “Corporation,” “St” into “Street,” and “(555) 867-5309” into a consistent digit string. Name parsing splits “Dr. Robert James Smith III” into title, first, middle, last, and suffix, and this step alone materially improves match accuracy because many apparent non-matches are simply formatting differences.
Stage 4: Block and Index
Blocking partitions the dataset into comparison groups to make pairwise matching feasible, since comparing every record to every other in a 10-million-row dataset would require roughly 50 trillion comparisons. Blocking on the first three characters of last name plus ZIP code reduces that to a manageable number, and the best platforms support multiple overlapping blocking keys plus adaptive blocking that selects keys based on the data.
Stage 5: Match and Score
Within each block, the software compares record pairs across multiple fields using layered algorithms, a typical configuration applying Jaro-Winkler similarity on names, Levenshtein distance on addresses, exact matching on email, and Double Metaphone as a secondary name check. Each comparison produces a similarity score, and the platform combines them into a weighted composite where higher-reliability fields carry more weight.
Stage 6: Classify, Review, and Merge
Records above the auto-merge threshold (typically 90 and above on a 100-point scale) are merged automatically using survivorship rules, records in the review zone (typically 70 to 89) are routed to a manual queue with side-by-side comparisons, and records below are classified as distinct. The merged output is a golden record for each entity with a full audit trail, and the consolidation workflow itself is covered in the merge purge process.
What Do Duplicate Records Actually Cost?
Duplicate records impose costs across every department that relies on data, inflating operating expenses, reducing revenue, and creating compliance risk. The pattern is consistent across industries, and putting a defensible number on it for your own environment is the work of the cost of duplicate records analysis.
The arithmetic is straightforward once the per-duplicate cost is known. A large hospital system with a high duplicate rate across millions of patient records can carry hundreds of thousands of duplicates, and resolving even a fraction returns more than the cost of the platform.
Where Does Your Organization Fall on the Deduplication Maturity Scale?
Not every organization needs the same level of deduplication capability. A five-level maturity model helps teams assess their current state and plan a practical path forward.
Case Scenario: Deduplication Before an EHR Migration
A 400-bed hospital system preparing to migrate from three legacy EHR platforms to a single instance found that its combined patient master index held 3.2 million records. An initial profile estimated a duplicate rate of 16.4 percent, roughly 525,000 records representing patients already in the system under a different medical record number.
The team configured matching across five fields: first name (Jaro-Winkler, weight 20 percent), last name (Jaro-Winkler, 25 percent), date of birth (exact, 25 percent), the last four digits of SSN (exact, 20 percent), and address (composite Levenshtein, 10 percent), with blocking on the first two characters of last name plus birth year. The initial automated pass resolved about 412,000 records above the 92-point threshold, another 68,000 entered manual review, and the remainder needed clinical review for conflicting medication histories.
Post-deduplication, the unique patient count dropped from 3.2 million to 2.74 million, and the migration proceeded with a clean master patient index. That eliminated what the project team estimated would have been a substantial post-migration remediation cost.
What Should Enterprise Buyers Prioritize When Evaluating Data Deduplication Software?
The right criteria depend on your maturity level, data volume, regulatory environment, and number of source systems, but five priorities apply universally.
- Test on your own data: Vendor demos use curated datasets that hide the inconsistencies, missing fields, and legacy artifacts in your production data, so request a proof of concept against a representative sample before signing.
- Evaluate survivorship as carefully as matching: Identifying duplicates is necessary but not sufficient; field-level survivorship with conditional logic is what determines whether the golden record is actually better than any single source record.
- Confirm deployment compatibility: For regulated industries, on-premise or private deployment is often non-negotiable, and the broader evaluation criteria are laid out in the dedupe software comparison.
- Plan for continuous operations: One-time batch deduplication clears the backlog but does not prevent re-accumulation, so check for incremental matching, scheduled runs, and real-time API integration.
- Require full audit trails: Every merge decision, survivorship rule, and review outcome should be logged with timestamps and user attribution, the same lineage expected across data matching software generally.
Putting Deduplication Software to Work
Data deduplication software earns its place when it raises match accuracy on your real data, gives you field-level control over the golden record, and proves every merge with an audit trail. MatchCore provides that engine on-premise, with layered matching, configurable survivorship, and logged lineage, and processes large volumes on standard enterprise hardware. For persistent cross-system identities beyond a single dedup run, MatchSense adds explainable AI entity resolution on the same footprint.
Frequently Asked Questions
What is the difference between data deduplication software and data cleansing software?
Data deduplication software specifically targets duplicate records: finding, scoring, and resolving records that represent the same entity. Data cleansing software addresses a broader set of issues including formatting inconsistencies, invalid values, and missing fields. Most enterprise deduplication platforms include cleansing and standardization as preprocessing steps, because clean data produces more accurate matching, but the two categories are not interchangeable.
How does data deduplication software handle false positives?
False positives, records incorrectly flagged as duplicates, are managed through configurable match thresholds and manual review queues. Records above the auto-merge threshold merge automatically, while records in the gray zone are routed to reviewers who see side-by-side comparisons with field-level scores. A narrower gray zone means more automation but higher false-positive risk; a wider one means more manual review but fewer errors.
Can data deduplication software work with unstructured data?
Record-level deduplication operates on structured or semi-structured data: database tables, CSV files, and CRM records. Unstructured data such as PDFs, emails, and free-text notes usually needs extraction and parsing into structured fields first. Some platforms include text extraction; others require a separate data preparation step before deduplication can run.
How often should an enterprise run deduplication?
Frequency should match the rate at which new data enters the system. A CRM ingesting thousands of new leads a week should run incremental deduplication daily, while a warehouse refreshed monthly can deduplicate on each refresh. The most mature organizations run real-time deduplication at the point of entry, preventing duplicates from ever being committed.
Is open-source deduplication software viable for enterprise use?
Open-source tools such as dedupe.io and OpenEMPI provide matching algorithms but lack the surrounding enterprise infrastructure: GUI configuration, survivorship management, multi-source connectors, audit trails, and vendor support. They suit teams with strong data engineering skills and modest volumes. For millions of records across multiple systems with audit requirements, commercial platforms provide the operational reliability that open-source alternatives do not.
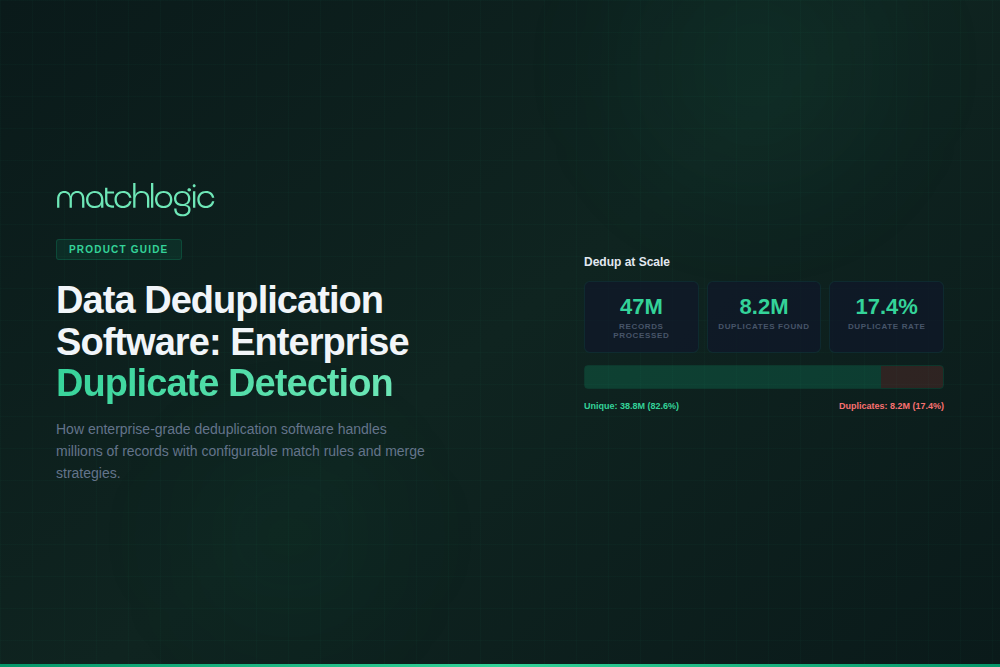
What record volumes can enterprise deduplication software handle?
Enterprise platforms are built for datasets from hundreds of thousands to hundreds of millions of records, with performance depending on algorithm complexity, blocking keys, and hardware. MatchLogic processes 10 million records in minutes on standard enterprise hardware. The metric that matters is not just single-run throughput but sustained performance across incremental runs as the master dataset grows.





.svg)