
What Is Dedupe Software?
Dedupe software identifies, flags, and resolves duplicate records within and across databases, CRMs, data warehouses, and other enterprise systems. It should not be confused with the file-level deduplication used in backup and storage, which strips redundant data blocks to save disk space. Record-level dedupe works on structured data, where one real-world entity (a customer, vendor, patient, or product) shows up as several slightly different records.
That distinction matters because search results for "dedupe software" routinely blur the two. Storage deduplication shrinks backup volumes. Record deduplication fixes the data quality problems that distort analytics, waste spend, and erode trust in reporting. This article covers the second category: enterprise record deduplication.
The cost is concrete. Duplicate records inflate marketing spend on redundant contacts, corrupt customer counts and revenue attribution, trigger duplicate shipments and billing, and quietly degrade every downstream system fed by the data. IBM's often-cited estimate put the annual cost of poor-quality data in the US at roughly $3.1 trillion, though that 2016 figure is best treated as directional rather than precise.
Duplicates are among the most common and measurable contributors to that cost. Rates vary by system, but CRMs that ingest data from many channels tend to accumulate the highest share, since every new source adds another chance to create a near-match instead of updating the existing record.
Why Do Enterprise Organizations Need Dedicated Dedupe Software?
CRMs like Salesforce and HubSpot include basic built-in deduplication, but those native tools rely on exact-match rules (identical email address or phone number) and miss the majority of real-world duplicates. “Robert Smith” and “Bob Smith” at the same address are different records in a native deduper, and “Acme Corp” and “ACME Corporation” remain two separate accounts. Before investing, quantifying the cost of duplicate records in your own environment is what builds the business case.
Enterprise dedupe software applies multiple matching techniques in layers. Phonetic algorithms (Soundex, Metaphone, NYSIIS) catch names that sound alike but are spelled differently, string similarity algorithms (Jaro-Winkler, Levenshtein distance) catch typos and abbreviations, and probabilistic models assign weighted scores to each field comparison to calculate an overall match confidence. This layered approach is how platforms built for it reach high accuracy on enterprise datasets where native CRM tools plateau at 60 to 70 percent, and a deeper algorithm comparison sits in the fuzzy matching software guidance.
What Features Should You Evaluate in Dedupe Software?
Not all dedupe tools serve the same purpose. A plugin that merges obvious duplicates within a single CRM is a different product than an enterprise platform that deduplicates 50 million records across six source systems. The seven features below separate enterprise-grade dedupe software from point tools.
1. Matching Algorithm Depth
The matching engine is the core of any dedupe tool. Evaluate whether the software supports deterministic (rule-based), probabilistic (weighted scoring), and fuzzy matching methods, because a tool limited to deterministic matching will miss duplicates with misspellings, abbreviations, and formatting differences. Look for configurable match thresholds, field-level weighting, and support for domain-specific algorithms such as medical record number matching or DUNS number matching for B2B.
2. Survivorship and Merge Rules
Identifying duplicates is only half the problem, because when three records represent the same customer the software must decide which field values survive into the merged golden record. Weak tools offer only “most recent wins” or “longest value wins,” while enterprise tools provide field-level logic: the most recent phone number, the earliest creation date, the most complete address, and the email from the system of record. Without configurable survivorship, every merge risks data loss.
3. Blocking and Indexing Strategy
Comparing every record to every other record in a database of 10 million rows would require roughly 50 trillion pairwise comparisons. Blocking algorithms partition the dataset into smaller groups that share a common attribute, such as the first three characters of a last name or a ZIP code, so the software only compares records within the same block. Effective blocking reduces processing by orders of magnitude without sacrificing match quality, so evaluate support for multiple blocking keys, adaptive blocking, and cross-block matching for edge cases.
4. Scalability and Performance
Enterprise datasets range from hundreds of thousands to hundreds of millions of records. Test the software against your actual data volumes, not vendor benchmarks on synthetic data, and ask how long a full run takes on 10 million records, whether performance degrades linearly or exponentially, and whether incremental deduplication is supported.
5. Deployment Model: On-Premise or Cloud
For organizations in regulated industries, the deployment model is often the first filter. Data residency requirements under HIPAA, GDPR, and SOX may prohibit sending production data to a cloud-hosted service, so on-premise deployment that keeps all data within your network perimeter and under your security controls matters. Cloud-only tools require data exports or direct connections to external servers, each of which introduces compliance risk.
6. Data Connectivity and Source Support
Enterprise deduplication rarely involves a single database, since you may need to deduplicate across Salesforce, SAP, Oracle, SQL Server, flat files, and cloud warehouses at once. Evaluate the number and depth of native connectors, because a tool with Salesforce and HubSpot connectors but no ODBC, JDBC, or flat-file support will not serve a multi-system environment.
7. Auditability and Lineage Tracking
In regulated industries, you must be able to prove why two records were merged and which field values came from which source. Audit trails should capture the match score, the algorithms used, the survivorship rules applied, and a timestamp for every merge, because a tool that cannot produce this trail is not suitable for environments governed by SOX Section 404, HIPAA, or GDPR Article 17.
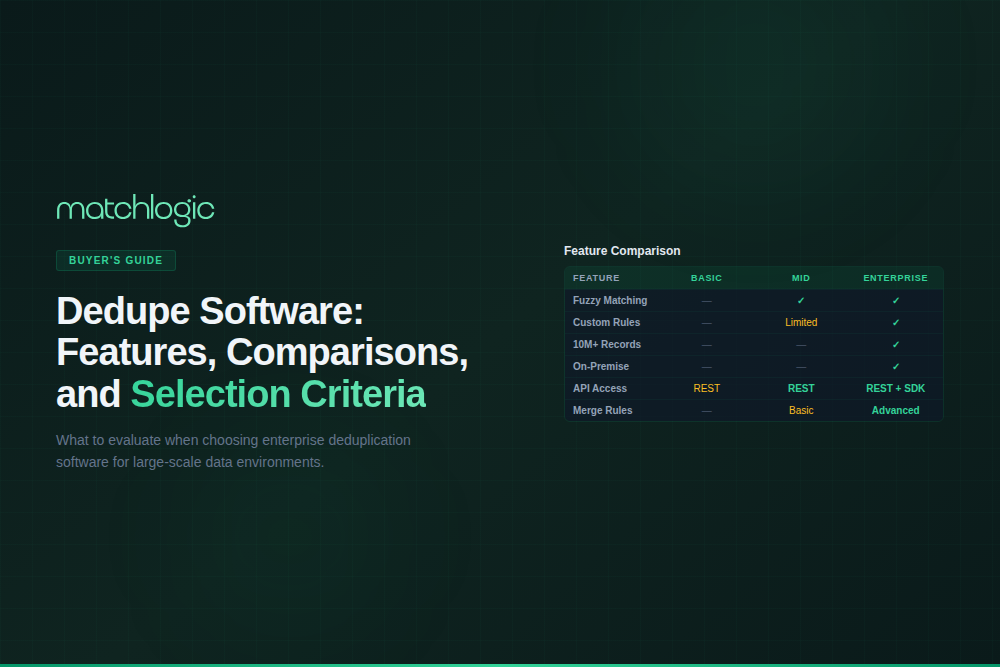
How Do Leading Dedupe Software Platforms Compare?
The table compares enterprise dedupe capabilities across the seven evaluation criteria, focusing on record-level deduplication tools rather than storage or backup appliances.
Note: This comparison reflects publicly available product documentation and independent reviews as of 2026, and capabilities vary by edition and version. Informatica's data quality tooling has shifted toward cloud-first architectures.
What Does the Enterprise Deduplication Process Look Like?
Deduplication is not a single operation; it is a pipeline with distinct stages, each requiring different configuration and oversight. Understanding the pipeline is critical for evaluating how well a tool fits your workflow.
Step 1: Data Profiling
Before matching begins, profile the data to understand field completeness, format consistency, and duplicate density. A 400-bed hospital migrating from three legacy EHR systems might find that 18 percent of patient records lack a date of birth, 12 percent have inconsistent address formats, and 8 percent are exact-match duplicates before fuzzy matching even starts. Profiling quantifies the problem and shapes the matching strategy.
Step 2: Standardization
Standardize field values so matching algorithms compare like with like: convert “St.” to “Street,” “Corp” to “Corporation,” parse compound names into components, and normalize phone numbers. This step directly improves accuracy by eliminating surface-level differences that would otherwise generate false negatives.
Step 3: Blocking
Partition the dataset into candidate groups using keys such as the first three letters of a last name plus ZIP code, a phonetic encoding of company name, or date of birth plus gender. Effective blocking reduces the number of pairwise comparisons from the O(n squared) worst case to a manageable number without excluding true matches.
Step 4: Pairwise Comparison and Scoring
Within each block, compare record pairs across multiple fields, where each comparison yields a similarity score such as a Jaro-Winkler score of 0.92 on a name or a Levenshtein distance of 1 on a street address. The software combines these field-level scores into an overall match confidence, typically on a 0 to 100 scale.
Step 5: Classification and Review
Records above the auto-merge threshold (for example, 90 and above) are merged automatically, records in the gray zone (for example, 70 to 89) go to a manual review queue, and records below are classified as non-matches. The width of the gray zone and the accuracy of the automated merges are where enterprise dedupe software earns its value.
Step 6: Merge and Survivorship
Apply survivorship rules to create the golden record, where every field traces back to a source record: the most complete address from one record, the most recent phone from another, the verified email from a third. The audit trail logs every decision, and the full workflow, including preview and rollback, is the subject of the merge purge process.
Case Scenario: Deduplication at a Multi-Brand Retailer
A multi-brand retailer with 12 million customer records across four e-commerce platforms and two in-store POS systems ran an initial profile and found a 28 percent duplicate rate. The duplicates were concentrated in customers who purchased from multiple brands, data-entry variations from in-store staff (“Catherine” versus “Cathy” versus “Kathy”), and records created through the acquisition of a competitor brand.
Using a layered approach with phonetic encoding on names, Jaro-Winkler similarity on addresses, and exact matching on email domains, the retailer reduced the duplicate rate to 2.1 percent after the first automated pass. The manual review queue held about 14,000 records, mostly family members at the same address, and the retailer reclassified its unique customer count from 12 million to 8.6 million, which changed its lifetime-value calculations, segmentation, and loyalty economics.
What Are the Most Common Mistakes When Selecting Dedupe Software?
Mistake 1: Evaluating with Clean Sample Data
Vendors provide demo datasets that showcase their engine's strengths, but your data is different: inconsistent formats, missing fields, multilingual names, and legacy artifacts. Always test against a representative sample of your actual production data, including its messiest segments, because a tool that scores 98 percent on the vendor sample and 72 percent on your data is not a 98 percent tool.
Mistake 2: Ignoring Survivorship Complexity
Many evaluations focus on match accuracy and ignore what happens after the match. If the tool cannot handle field-level survivorship, conditional logic, and exception handling for conflicting values, the merge process will either lose data or require extensive manual intervention.
Mistake 3: Choosing Cloud When Compliance Requires On-Premise
Cloud-hosted tools require that your data leave your network. For organizations subject to HIPAA, GDPR data residency requirements, or internal governance policies that prohibit third-party data transfers, that disqualifies cloud-only platforms regardless of matching capability, so evaluate deployment model as a pass-or-fail criterion before evaluating features.
What Are the Different Types of Record Deduplication?
Record-level deduplication is not a single operation, and the type you need depends on whether you are cleaning within one system, linking across systems, or maintaining ongoing quality. Platform-level data deduplication software usually supports several of the modes in the table below.
Most enterprise environments combine batch and incremental deduplication: the initial batch run clears the historical backlog, and incremental runs maintain quality going forward. Real-time deduplication at the point of entry is the highest-maturity approach, preventing duplicates from ever entering the system.
Choosing Dedupe Software That Fits
The right dedupe tool matches your data volume, your source systems, and your compliance constraints, and it proves every merge with an audit trail an examiner can read. MatchCore provides the on-premise engine for this work, with layered deterministic, fuzzy, and probabilistic matching, field-level survivorship, and a logged trail for every merge. For teams that also need persistent cross-system identities, MatchSense adds explainable AI entity resolution on the same on-premise footprint.
Frequently Asked Questions
What is the difference between dedupe software and data matching software?
Dedupe software is a subset of data matching software. Data matching identifies related records across or within datasets for linkage, enrichment, and deduplication, while dedupe software focuses specifically on identifying and resolving duplicate records that represent the same entity. All dedupe software uses data matching, but not all data matching software is built for deduplication workflows.
How much does enterprise dedupe software cost?
Pricing varies by vendor and deployment model. CRM-specific plugins range from about $5,000 to $25,000 a year, mid-market platforms with fuzzy matching typically cost $25,000 to $75,000 annually, and enterprise platforms with on-premise deployment and multi-source connectors range higher depending on record volume. Always factor in implementation, training, and ongoing support when calculating total cost of ownership.
Can dedupe software handle multilingual data?
Enterprise-grade dedupe software supports multilingual data through locale-specific phonetic algorithms, Unicode-aware string comparison, and configurable transliteration rules. Matching “Muller” and “Müller,” for example, requires algorithms designed for specific character sets and naming conventions. Not all tools support this, so verify multilingual matching on your specific languages during evaluation.
How long does a typical enterprise deduplication project take?
Timeline depends on data volume, the number of source systems, and survivorship complexity. A single-source CRM deduplication of 500,000 records can finish in 2 to 4 weeks including profiling, configuration, testing, and the production run, while a multi-source project spanning five or more systems and 20 million records typically takes 8 to 16 weeks. The engine processes millions of records in minutes to hours; most project time goes to profiling, rule configuration, and review of edge cases.
What is a golden record in deduplication?
A golden record is the single authoritative version of an entity created by merging the best available data from all duplicate records. It contains the most complete, most accurate, and most current field values as determined by survivorship rules. If three duplicate customer records exist, the golden record might combine the most recent email from one, the most complete address from another, and the original creation date from a third.
Does deduplication delete records permanently?
Properly configured dedupe software does not permanently delete source records. Non-destructive deduplication links duplicates to a golden record while retaining the originals in an archive or audit log, which preserves lineage, supports GDPR right-of-access obligations, and allows merges to be reversed if rules change later. Any tool that permanently deletes records without an undo mechanism is unsuitable for enterprise use.





.svg)